Java线程
java 并发线程相关
线程状态

- 新建(NEW): 创建后尚未启动。
- 可运行(RUNABLE): 正在 Java 虚拟机中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层操作系统的资源调度。
- 阻塞(BLOCKED): 请求获取 monitor lock 从而进入 synchronized 函数或者代码块,但是其它线程已经占用了该 monitor lock,所以出于阻塞状态。要结束该状态进入从而 RUNABLE 需要其他线程释放 monitor lock。
- 无限期等待(WAITING): 等待其它线程显式地唤醒。
- 阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
- 限期等待(TIMED_WAITING): 无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
- 调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep() 方法 | 时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
- 死亡(TERMINATED): 可以是线程结束任务之后自己结束,或者产生了异常而结束。
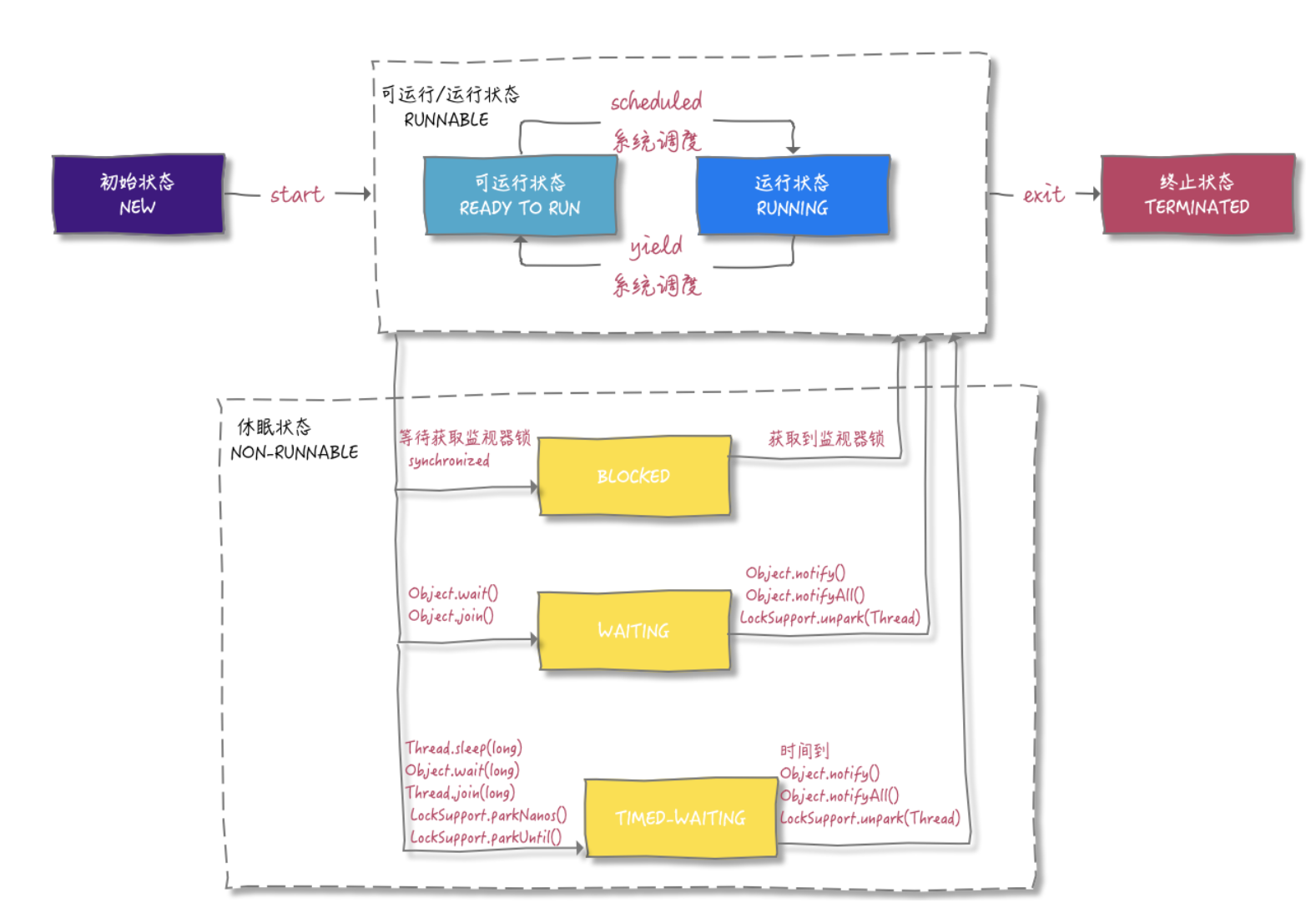
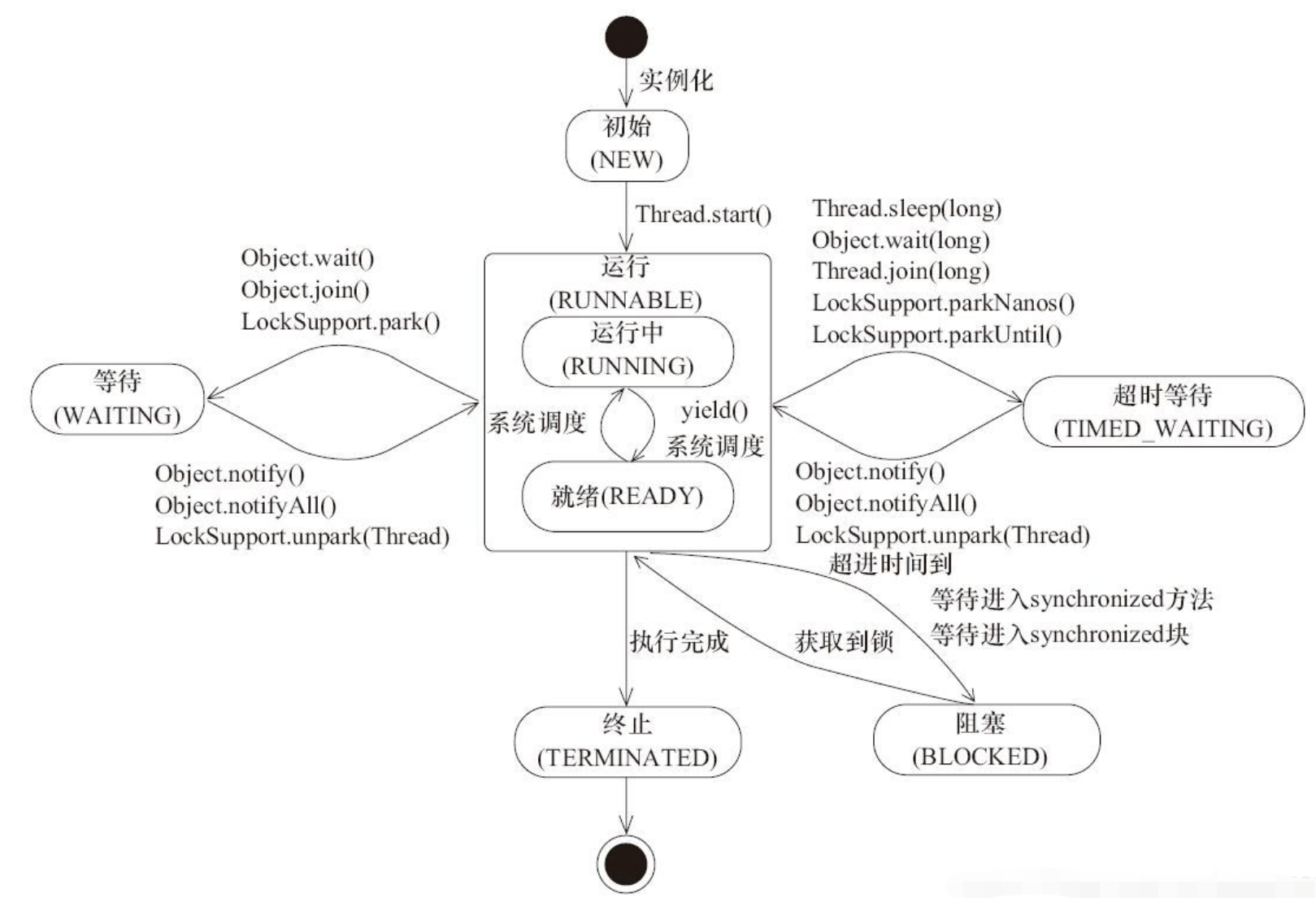
线程方法与状态切换
sleep 导致当前线程休眠,与 wait 方法不同的是 sleep 不会释放当前占有的锁,sleep(long)会导致线程进入 TIMED-WATING 状态,而 wait()方法会导致当前线程进入 WATING 状态
wait 方法,主动让出锁。
- 不带时间常数的wait 方法进入WAITING状态。
- 带时间常数的wait 进入TIME-WAITING状态。
yield 方法,线程让步。 yield 会使当前线程让出 CPU 执行时间片,与其他线程一起重新竞争 CPU 时间片。一般情况下,优先级高的线程有更大的可能性成功竞争得到 CPU 时间片
join方法,当前线程转为阻塞状态,等到另一个线程结束,当前线程再由阻塞状态变为就绪状态,等待 cpu 的宠幸。
join方法可用于多线程的协作,如主子线程的协作,主线程等待子线程完成任务。
join 方法的状态转换与wait方法相同,带时间的进入TIME-WAITING状态,不带时间的进入WAITING状态。
1 | |
创建一个线程的开销
JVM 在背后帮我们做了哪些事情:
- 它为一个线程栈分配内存,该栈为每个线程方法调用保存一个栈帧
- 每一栈帧由一个局部变量数组、返回值、操作数堆栈和常量池组成
- 一些支持本机方法的 jvm 也会分配一个本机堆栈
- 每个线程获得一个程序计数器,告诉它当前处理器执行的指令是什么
- 系统创建一个与Java线程对应的本机线程
- 将与线程相关的描述符添加到JVM内部数据结构中
- 线程共享堆和方法区域
用数据来说明创建一个线程(即便不干什么)需要多大空间呢?
答案是大约 1M 左右。java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics -version
用 Java8 的测试结果,19个线程,预留和提交的大概都是19000+KB,平均每个线程大概需要 1M 左右的大小
创建线程的方式
- callable 接口继承: 可以获取线程的返回值。
Future接口 相当于 Runnable接口
FutureTask类 类似于Thread类,最后执行调用都要使用Thread类
1 | |
- Runnable接口实现 与 继承Thread
1 | |
退出线程的方法
虚拟机级别的中断方式
- 线程中使用一个静态的volatile的标志判断退出。
- 调用Executors的submit方法,获取线程上下文对象Future,调用cancel方法。(注: 无法中断正在试图获取synchronized锁或者试图执行I/O操作的线程)IO的中断,关闭底层资源之后,任务将解除阻塞。如socket连接,调用socket的close 或者 system.in 的输入连接调用in.close().
- 调用ExecutorService的shutdown的方法。
- 通过检查中断状态Thread.interrupted(),主动调用Thread的interrupt方法实现。(注意处理的时候,如果线程已经调用了interrupt(),如果再调用sleep方法,将抛出interruptException的异常)
- 与Runnable相关: 主要是通过调用
Thread.interrupt方法实现。 - 与Callable相关: 可以调用Future对象的cancel(true)方法。
基于ReentrantLock
ReentrantLock调用锁的lockInterruptibly()方法,
lock(), 拿不到lock就不罢休,不然线程就一直block。tryLock(),马上返回,拿到lock就返回true,不然返回false。带时间限制的tryLock(),拿不到lock,就等一段时间,超时返回false。比较聪明的做法。lockInterruptibly()就稍微难理解一些。
先说说线程的打扰机制,每个线程都有一个 打扰 标志。这里分两种情况,
- 线程在sleep或wait、join, 此时如果别的进程调用此进程的 interrupt()方法,此线程会被唤醒并被要求处理InterruptedException;(thread在做IO操作时也可能有类似行为,见java thread api)
- 此线程在运行中,则不会收到提醒。但是 此线程的 “打扰标志”会被设置, 可以通过isInterrupted()查看并 作出处理。
- 结论:
lockInterruptibly()和上面的第一种情况是一样的, 线程在请求lock并被阻塞时,如果被interrupt,则“此线程会被唤醒并被要求处理InterruptedException”。并且如果线程已经被interrupt,再使用lockInterruptibly的时候,此线程也会被要求处理interruptedException
中断标志Interrupt
中断一个线程,其本意是给这个线程一个通知信号,会影响这个线程内部的一个中断标识位。 这个线程本身并不会因此而改变状态(如阻塞,终止等)。
- 调用
interrupt()方法并不会中断一个正在运行的线程。也就是说处于Running状态的线程并不会因为被中断而被终止,仅仅改变了内部维护的中断标识位而已。 - 若调用
sleep()而使线程处于TIMED-WATING状态,这时调用interrupt()方法,会抛出InterruptedException,从而使线程提前结束TIMED-WATING状态。 - 许多声明抛出 InterruptedException 的方法,抛出异常前,都会清除中断标识位,所以抛出异常后,调用
isInterrupted()方法将会返回 false - 利用中断标识,可以调用
thread.interrupt()方法,在线程的 run 方法内部可以根据thread.isInterrupted()的值来优雅的终止线程。
线程池
1 | |
线程池的主要状态锁,对线程池状态(比如线程池大小、runState等)的改变都要使用这个锁
线程池状态
线程池的5种状态: Running、ShutDown、Stop、Tidying、Terminated。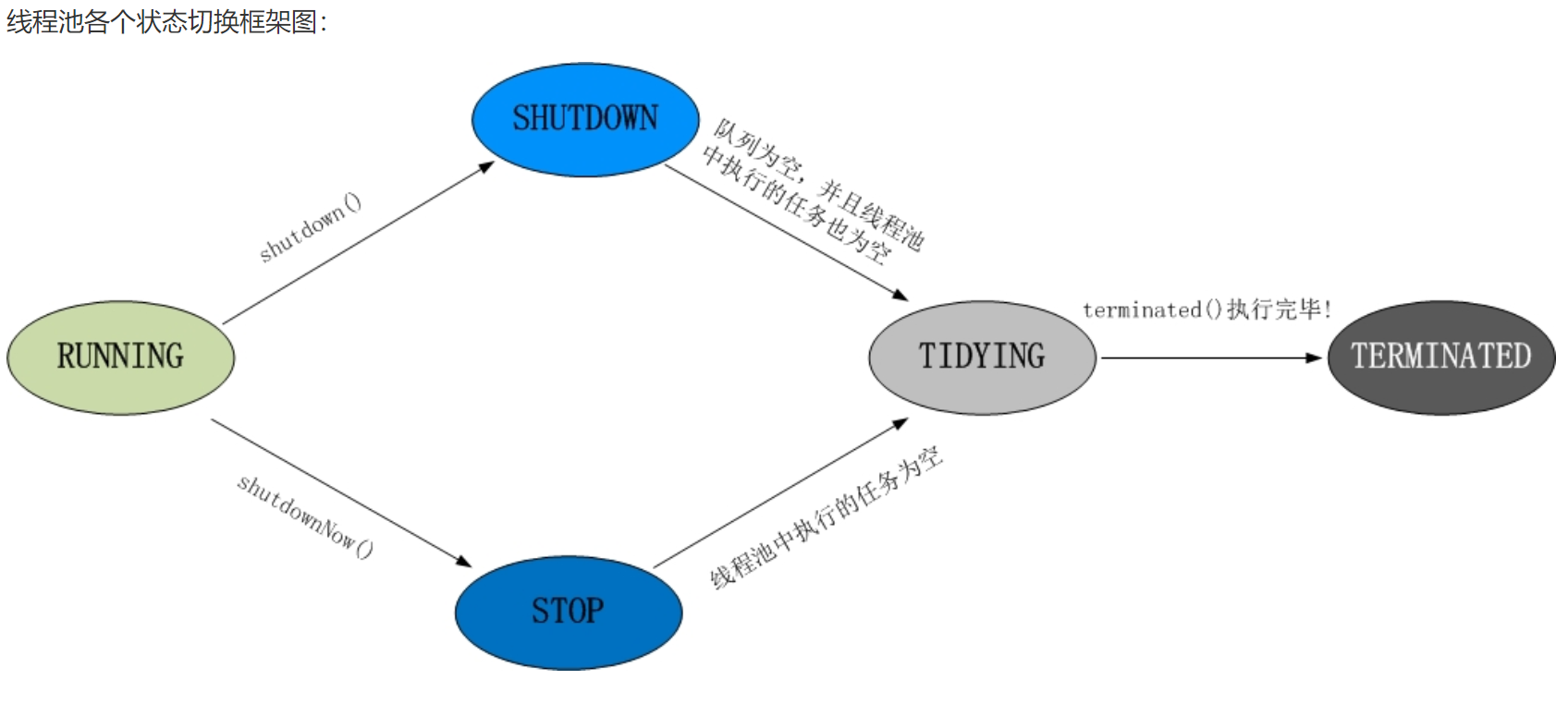
RUNNING
- 状态说明: 线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
- 状态切换: 线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态
SHUTDOWN
- 状态说明: 线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
- 状态切换: 调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
STOP
- 状态说明: 线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
- 状态切换: 调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
TIDYING
- 状态说明: 当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
- 状态切换: 当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。
TERMINATED
- 状态说明: 线程池彻底终止,就变成TERMINATED状态。
- 状态切换: 线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
线程池创建
线程池的初始化:
1 | |
corePoolSize: 核心线程数量,当有新任务在execute()方法提交时,会执行以下判断:
- 如果运行的线程少于
corePoolSize,则创建新线程来处理任务,即使线程池中的其他线程是空闲的; - 如果线程池中的线程数量大于等于
corePoolSize且小于maximumPoolSize,则只有当workQueue满时才创建新的线程去处理任务; - 如果设置的
corePoolSize和maximumPoolSize相同,则创建的线程池的大小是固定的,这时如果有新任务提交,若workQueue未满,则将请求放入workQueue中,等待有空闲的线程去从workQueue中取任务并处理; - 如果运行的线程数量大于等于
maximumPoolSize,这时如果workQueue已经满了,则通过handler所指定的策略来处理任务 - 所以,任务提交时,判断的顺序为
corePoolSize–>workQueue–>maximumPoolSize。
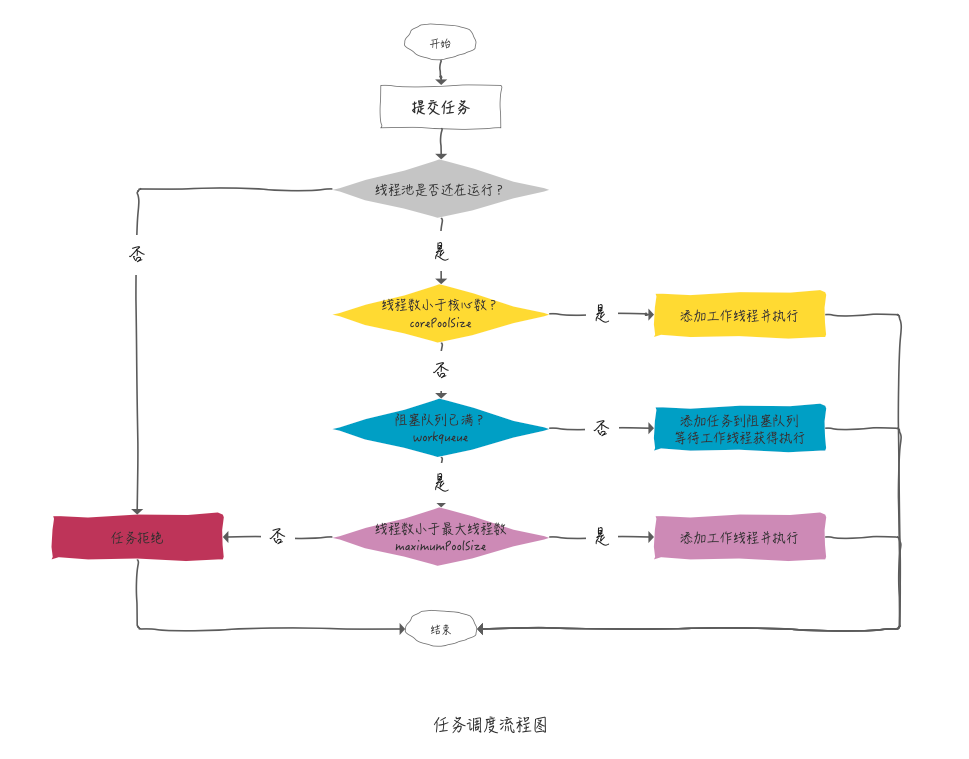
线程池拒绝策略
ThreadPoolExecutor.AbortPolicy: 抛出 RejectedExecutionException来拒绝新任务的处理。ThreadPoolExecutor.CallerRunsPolicy: 提交任务的线程自己去执行该任务ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
线程池的队列 五种
Executors.newFixedThreadPool():new LinkedBlockingQueue<Runnable>()Executors.newSingleThreadExecutor():new LinkedBlockingQueue()
以上两种创建的方式不推荐,因为使用了linkedBlockingQueue的无界队列,会导致最大线程数以及多余核心的keepalive的参数失效。 而因为无初始值的
new LinkedBlockingQueue()是无界队列的关系,当任务过多会导致OOM
Executors.newCachedThreadPool():new SynchronousQueue<Runnable>()
不推荐用newCacheThreadPool的原因是因为最大线程数设置为Integer.MAX_VALUE,如果主线程提交任务的速度高于 maximumPool 中线程处理任务的速度时,会耗尽CUP及内存。
Executors.newScheduledThreadPool():new DelayedWorkQueue()中封装了一个 PriorityQueue
任务队列 DelayedWorkQueue 封装了一个 PriorityQueue,PriorityQueue 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行(ScheduledFutureTask 的 time 变量小的先执行),如果执行所需时间相同则先提交的任务将被先执行(ScheduledFutureTask 的 squenceNumber 变量小的先执行)。
队列原理与 DelayQueue 基本一致
Executors.newWorkStealingPool(): 内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
工作窃取算法: 工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。一个大任务分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并未每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如线程1负责处理1队列里的任务,2线程负责2队列的。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务待处理。干完活的线程与其等着,不如帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。默认从其他队列的队尾开始窃取任务执行。
思想为: 充分利用线程进行并行计算,减少线程间的竞争。在某些情况下还是会存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源, 比如创建多个线程和多个双端队列。
1 | |
队列说明:
SynchronousQueue(CachedThreadPool)类似交警只是指挥车辆,并不管理车辆
SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。超出直接corePoolSize个任务,直接创建新的线程来执行任务,直到(corePoolSize+新建线程)> maximumPoolSize。不是核心线程就是新建线程。
LinkedBlockingQueue(single,fixed)类似小仓库,暂时存储任务,待系统有空的时候再取出执行
BlockingQueue是双缓冲队列。BlockingQueue内部使用两条队列,允许两个线程同时向队列一个存储,一个取出操作。在保证并发安全的同时,提高了队列的存取效率。不指定大小的LinkedBlockingQueue是一个无界缓存等待队列。当前执行的线程数量达到corePoolSize的数量时,剩余的元素会在阻塞队列里等待。(所以在使用此阻塞队列时maximumPoolSizes就相当于无效了),每个线程完全独立于其他线程。生产者和消费者使用独立的锁来控制数据的同步,即在高并发的情况下可以并行操作队列中的数据。
ArrayBlockingQueue
ArrayBlockingQueue是一个有界缓存等待队列,可以指定缓存队列的大小,当正在执行的线程数等于corePoolSize时,多余的元素缓存在ArrayBlockingQueue队列中等待有空闲的线程时继续执行,当ArrayBlockingQueue已满时,加入ArrayBlockingQueue失败,会开启新的线程去执行,当线程数已经达到最大的maximumPoolSizes时,再有新的元素尝试加入ArrayBlockingQueue时会报错
线程池相关方法
execute() VS submit()
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;submit()方法用于提交需要返回值的任务。线程池会返回一个 Future 类型的对象,通过这个 Future 对象可以判断任务是否执行成功,
shutdown() VS shutdownNow()
shutdown(): 关闭线程池,线程池的状态变为 SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。shutdownNow(): 关闭线程池,线程的状态变为 STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List。
isTerminated() VS isShutdown()
isShutDown当调用shutdown()方法后返回为 true。isTerminated当调用shutdown()方法后,并且所有提交的任务完成后返回为 true
线上线程池的配置
常规思路
CPU密集: CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),而在单核CPU上,无论你开几个模拟的多线程,该任务都不可能得到加速,因为CPU总的运算能力就那些。
IO密集型,即该任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行,即时在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
网络读取,文件读取这类都是 IO 密集型
对于不同性质的任务来说
CPU密集型任务应配置尽可能小的线程,如配置CPU个数的线程数+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。
计算密(CPU)集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作。
IO密集型任务应配置尽可能多的线程,因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量,如配置两倍CPU个数+1,
单核最佳线程数 =
(1/CPU利用率)=1 + (I/O耗时/CPU耗时)
最佳线程数 =CPU核心数 * (1/CPU利用率)=CPU核心数 * (1 + (I/O耗时/CPU耗时))
CPU利用率:(CPU耗时)/ (I/O耗时 + CPU耗时)
目前所有方案:
问题1:
假设要求一个系统的TPS(Transaction Per Second 或者 Task Per Second)至少为20,然后假设每个Transaction由一个线程完成,继续假设平均每个线程处理一个Transaction的时间为4s
如何设计线程个数,使得可以在1s内处理完20个Transaction?
答案: 一个线程平均1s处理1/4s=0.25个TPS请求,20/0.25=80。一般服务器的CPU核数为16或者32,如果有80个线程,那么肯定会带来太多不必要的线程上下文切换开销
问题2:
计算操作需要5ms,DB操作需要 100ms,对于一台 8 核CPU的服务器,怎么设置线程数呢?
答案:8 * (1/(5/100+5) = 168个线程数
那如果DB的QPS(Query Per Second)上限是1000,此时这个线程数又该设置为多大呢?
一个线程的TPS(每秒)处理任务数 =1000/105
系统的QPS = 168 * 1000/105 > 1600
假设一个 TPS 对应一次 QPS
答案: 线程数 =168* (1000/ 1600) > 105
增加服务器核心数,与线程间的关系
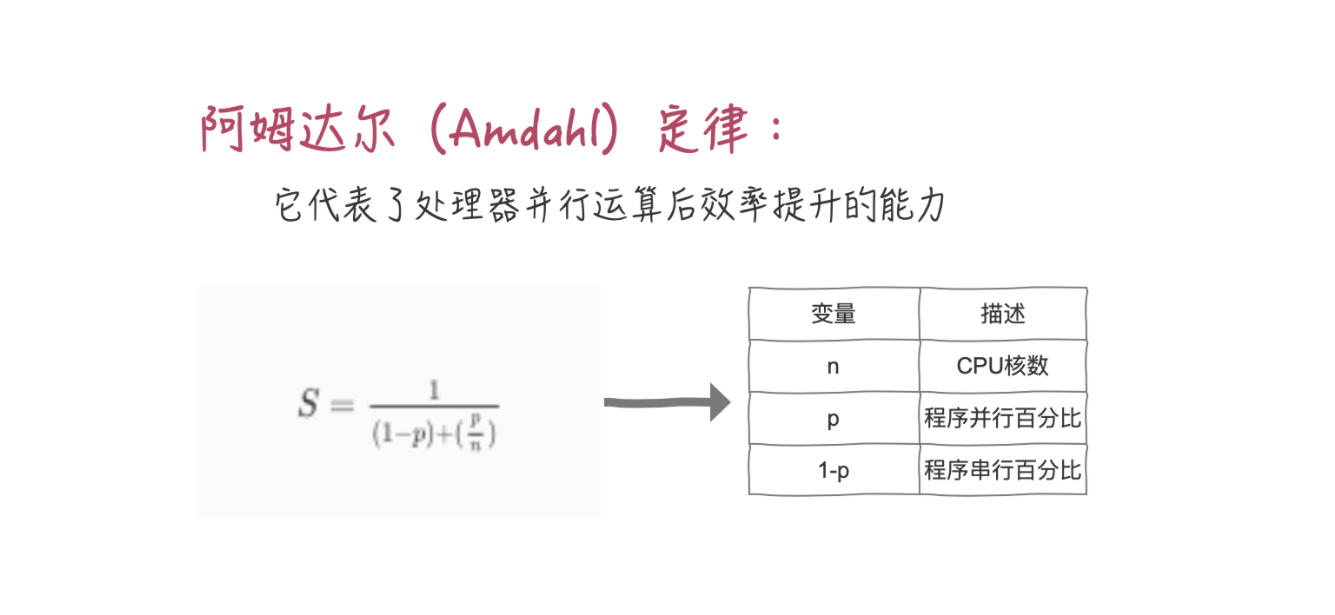
假设: 1-p=5% 而n趋近于无穷大,实际起作用的最大线程数为20。
临界区都是串行的,非临界区都是并行的,用单线程执行 临界区的时间/用单线程执行(临界区+非临界区)的时间 就是串行百分比
实际执行解决方案: 动态配置线程池核心线程数和最大线程数
1 | |
逻辑:
- 首先是参数合法性校验。
- 然后用传递进来的值,覆盖原来的值。
- 判断工作线程是否是大于最大线程数,如果大于,则对空闲线程发起中断请求。
注意点:
设置核心线程数的时候,同时设置最大线程数。否则若出现核心线程数大于最大线程数,在线程池getTask的任务处理中,会因为该问题导致设置不生效。
由于LinkedBlockingQueue的容量capacity为final类型的,需要动态修改队列的容量可以通过继承该queue声明一个可改变的capacity参数。
其他的tip
1
2
3
4// 预启动线程池的核心线程,对线程池进行预热
threadPoolExecutor.prestartAllCoreThreads();
// 回收核心线程的一个方案允许核心线程过期
threadPoolExecutor.allowCoreThreadTimeOut(true);使用以下工具来了解I/O 耗时与 CUP耗时
- SkyWalking
- CAT
- zipkin
相关资料
ThreadFactory 线程工厂
ThreadFactory 主要用于创建新线程对象,使用线程工厂就无需再手工编写对 new Thread 的调用了。
- 对于区分业务的线程池,就可以用到到命名线程工厂的实现,针对不同线程池资源定义不同的线程名
- 或者设置一个创建守护线程的线程工厂。
优点:
- 很容易改变的类创建的对象或我们创建这些对象的方式。
- 很容易用有限的资源限制的创建对象,例如,我们只能有N个对象。
- 很容易生成统计数据对创建的对象。
1 | |
Worker工作流程
1 | |
Worker为线程池内部对于线程的包装类,继承了AQS抽象类,实现了简单的不可重入的互斥锁。
- 使用AQS框架提供对线程的中断控制。
- 不可重入互斥,保证了在runWorker方法中执行的线程安全。 主要为了防止自我中断的现象发生。
- 因为RunWorker方法中存在beforeExecute、afterExecute的空插槽方法,若方法重写后调用了
setCorePoolSize(), 使用ReentrantLock会导致线程可重入,进而导致自我中断的现象发生。 - 另外线程中的实际执行方法也可能调用
setCorePoolSize()。
- 因为RunWorker方法中存在beforeExecute、afterExecute的空插槽方法,若方法重写后调用了
- Worker使用HashSet进行保存,通过ReentrantLock方法保证线程安全,控制Worker集合的修改。
1 | |
Worker 线程复用
线程复用主要通过while循环的去队列中获取任务getTask()
- 因为队列为阻塞队列,若为核心线程直接调用阻塞队列的take()方法。
- 若目前线程数超过核心线程,那么使用
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),未获取到新任务推出线程的while方法,进入销毁流程。
1 | |
超数量线程的销毁
- 超过核心线程数的线程在通过
getTask()方法中通过使用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)未获取到线程的 - 退出线程的while方法,进而进入到销毁流程。
- 销毁线程通过ReentrantLock获取WorkerSet的操作权限,进而移除线程。
相关资料
ThreadLocal
Thread 类存储了ThreadLocal.ThreadLocalMap 对象 : ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
- key: key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用WeakReference).
- ThreadLocalMap的key为每个新建的
ThreadLocal private void set(ThreadLocal<?> key, Object value) { }
ThreadMap的实现类似于HashMap,不过其数据结构仅使用数组,定义一个Entry的类,key为 WeakReference引用的ThreadLocal,value为存入的value。
- key的hash计算: 使用黄金分割数*AtomInteger计算,再根据容量确定索引位置。每次新增一个元素,AtomInteger都自动加一。
- 因为map的key都是threadLocal,所以在不set或remove元素的时候,每次get都是同一个元素的值。
set元素逻辑:
- hash定位到数组索引位置,如果位置无元素直接设值。
- 如果存在元素对比当前Entry key的hash 是否一致,一致则直接替换元素。
- 若不一致,向后一次找一个空位。
TheadMap的key为weakReference包裹的threadLocal 因此会存在被jvm回收的情况。使用在set的时如果遇到Entry是被回收的值,则触发探测性清理。
- 探测性清理: 以当前Entry 向后迭代查找,遇到为null则结束清理,遇到entry为空的值,清空数组位置,size–。非空的entry计算重哈希的位置。
- 启发性清理: 向后递归查找一个过期的位置,找到过期的位置触发探测性清理。
扩容: 扩容后的tab的大小为oldLen * 2,然后遍历老的散列表,重新计算hash位置,然后放到新的tab数组中,
在扩容、get和set的过程中遇到过期的键都会触发探测性清理。
父线程与子线程传递threadLocal的方案
- 阿里巴巴提供TransmittableThreadLocal组件: 父线程与子线程传递threadLocal的方案
- InheritableThreadLocal: 父线程与子线程共享threadLocal的方案,new Thread的时候会传递InheritableThreadLocal的解决方案。
缺陷需要在父线程中调用new Thread传递,而使用中新建线程都是使用线程池技术。
ThreadLocal应用
存在一个线程经常遇到横跨若干方法调用,需要传递的对象,也就是上下文(Context),它是一种状态,经常就是是用户身份、任务信息等,就会存在过渡传参的问题。
Spring 事务应用
- Spring采用ThreadLocal的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理connection对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
- Spring框架里面就是用的ThreadLocal来实现这种隔离,主要是在TransactionSynchronizationManager这个类里面.
- spring security 使用ThreadLocal 存储是否请求是否已经认证。
读写分离实现
- 使用theadLocal获取当前需要执行的数据源,结合AbstractDataSourceRouter执行需要执行的数据库。
ThreadLocalRandom 是ThreadLocal与 Random的结合,在Random的基础上进行性能的优化,在并发的情况下提供较大的性能提升。
Random 也是线程安全的类,内部使用AtomLong 结合 CAS技术实现,但是CAS技术在并发的情况下,性能比较糟糕。
ThreadLocalRandom 是通过为每个线程实例化一个随机数生成器,来减少系统开销和对资源的争用。
跨方法传递: 常规web服务接收到request的时候,经常有一些用户信息需要传递到service层。此时就可以使用ThreadLocal存储用户信息,每个service方法就不用写传递参数。
TheadLocal 与 SimpleDateFormat的应用
使用SimpleDataFormat的parse()方法,内部有一个Calendar对象,调用SimpleDataFormat的parse()方法会先调用Calendar.clear(),然后调用Calendar.add(),如果一个线程先调用了add()然后另一个线程又调用了clear(),这时候parse()方法解析的时间就不对了。
解决: 使用了线程池加上ThreadLocal包装SimpleDataFormat,再调用initialValue让每个线程有一个SimpleDataFormat的副本,从而解决了线程安全的问题,也提高了性能。
1 | |
如果是Java8应用,可以使用DateTimeFormatter代替SimpleDateFormat, 线程安全
相关资料
待补充资料: netty的fastThreadLocal
spring 中的线程池
如果我们需要在 SpringBoot 实现异步编程的话,通过 Spring 提供的两个注解会让这件事情变的非常简单。
- @EnableAsync: 通过在配置类或者Main类上加@EnableAsync开启对异步方法的支持。
- @Async 可以作用在类上或者方法上,作用在类上代表这个类的所有方法都是异步方法。
没有自定义Executor, Spring 将创建一个 SimpleAsyncTaskExecutor 并使用它。
1 | |
异步编程demo
1 | |