Java IO
Java IO
基本概念
Java 的 I/O 大概可以分成以下几类:
- 磁盘操作:File
- 字节操作:InputStream 和 OutputStream
- 字符操作:Reader 和 Writer
- 对象操作:Serializable
- 网络操作:Socket
- 新的输入/输出:NIO
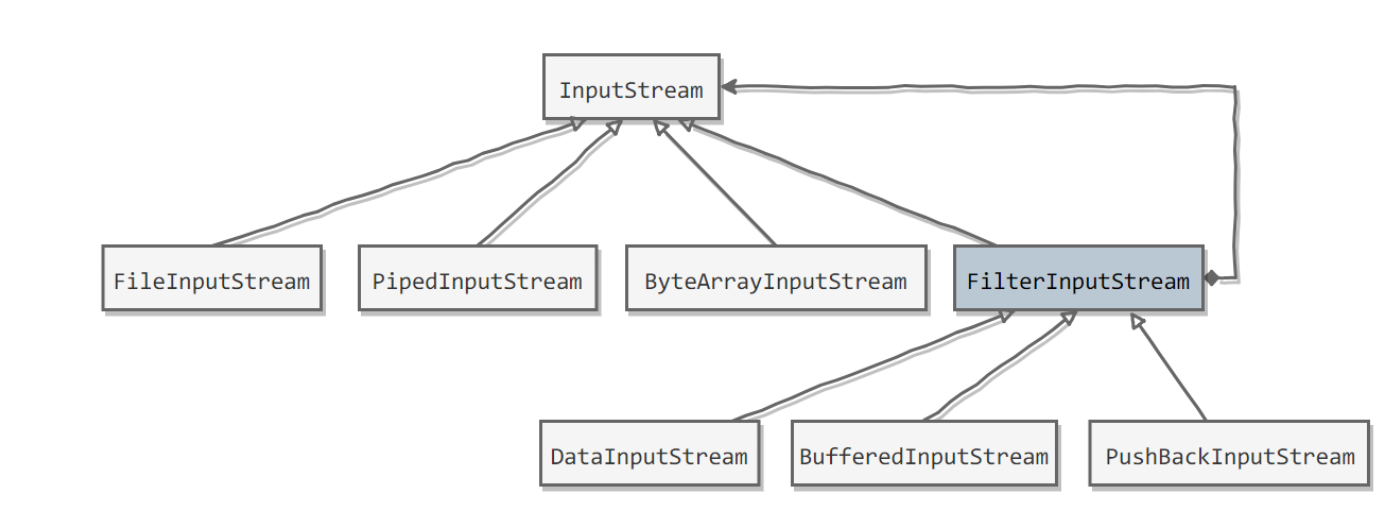
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了文件字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
InputStream的作用是用来表示那些从不同数据源产生输入的类。
- 字节数组
- String对象
- 文件
- “管道“,工作方式与实际管道类似,即一端输入另一端输出
- 其他数据源,如Internet连接等
Reader 与 Writer
- 不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
- InputStreamReader 实现从字节流解码成字符流;
- OutputStreamWriter 实现字符流编码成为字节流。
编码与解码
编码就是把字符转换为字节,而解码是把字节重新组合成字符。如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
String 编码转换
1 | |
操作系统中的IO
常见I/O模型对比
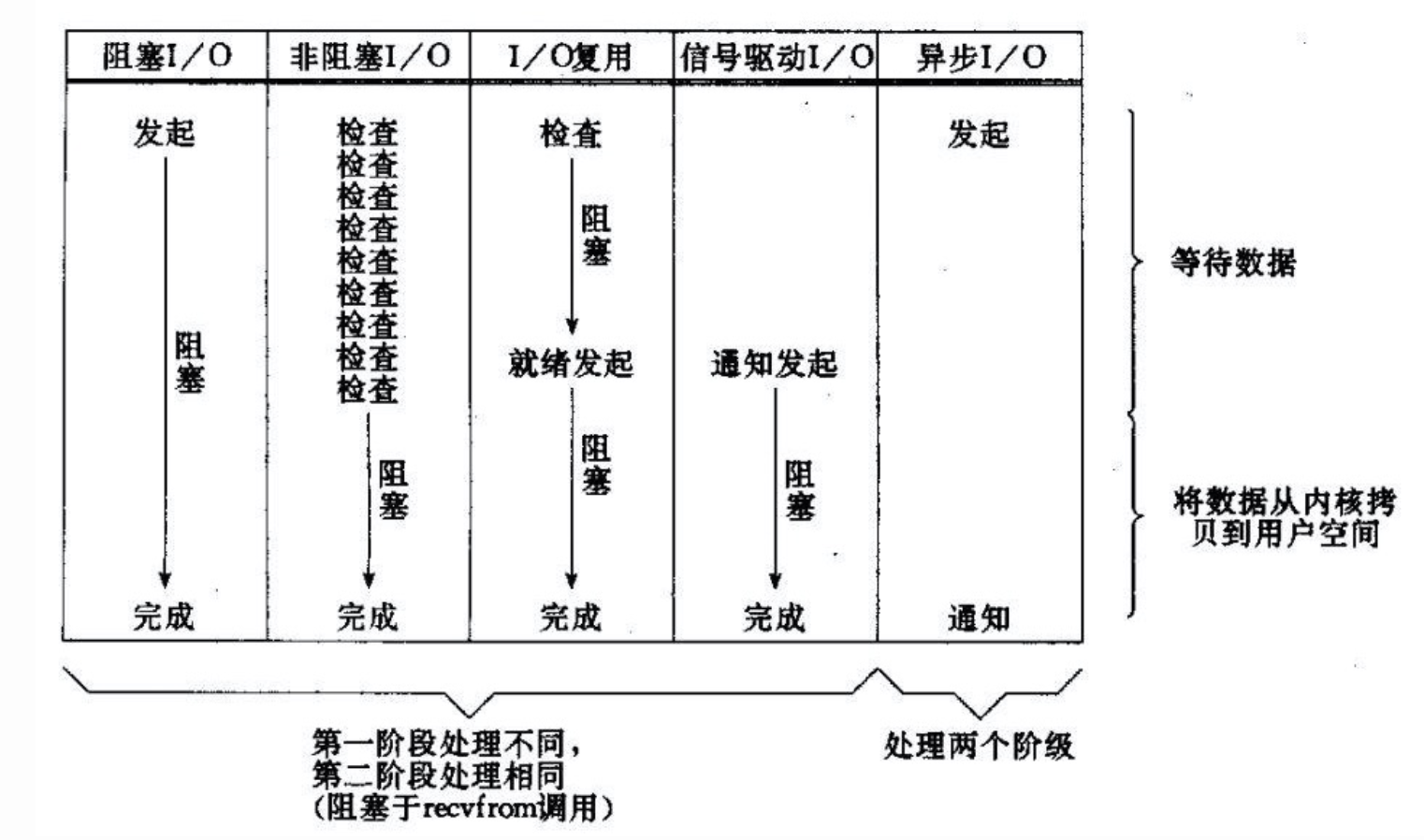
所有的系统I/O都分为两个阶段:等待就绪和操作。
举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
需要说明的是等待就绪的阻塞是不使用CPU的,是在“空等”;
而真正的读写操作的阻塞是使用CPU的,真正在”干活”,而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
BIO
传统的BIO中,read去读取网络的数据时,是无法预知对方是否已经发送数据的。因此在收到数据之前,能做的只有等待,直到对方把数据发过来,或者等到网络超时。
NIO
NIO模式下,系统调用read,如果发现没数据已经到达,就会立刻返回-1。使用轮询的方式,不断的尝试有没有数据到达。没有得到数据就等一小会再试继续轮询。
NIO解决了线程阻塞的问题 ,但是会带来两个新问题:
- 如果有IO连接都要检查,那么就得一个一个的read。这会带来大量的线程上下文切换(read是系统调用,每调用一次就得在用户态和核心态切换一次)
- 轮询的休息等待时间无法确定。这里是要猜多久之后数据才能到。等待时间设的太长,程序响应延迟就过大;设的太短,就会造成过于频繁的重试,干耗CPU而已。
IO复用模型
定义:多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互,告诉操作系统要监视这些IO是否有事件发生。阻塞读取操作系统epoll方法回调的通知消息。
特点及相关说明:
IO多路复用是要和NIO一起使用的。尽管在操作系统级别,NIO和IO多路复用是两个相对独立的事情。也可以只用IO多路复用 + BIO,这时效果还是当前线程被卡住,没有达到IO多路复用的通知请求到来的效果。
IO多路复用说的是多个Socket或IO连接,只不过操作系统是一起监听他们的事件而已。
多个数据流共享同一个TCP连接的场景的确是有,比如Http2 Multiplexing就是指Http2通讯中多个逻辑的数据流共享同一个TCP连接。但这与IO多路复用是完全不同的问题。
- IO多路复用的关键API调用(select,poll,epoll_wait)总是Block的
- IO多路复用和NIO一起仅仅是解决了调度的问题,避免CPU在这个过程中的浪费,使系统的瓶颈更容易触达到网络带宽,而非CPU或者内存。要提高IO吞吐,还是提高硬件的容量(例如,用支持更大带宽的网线、网卡和交换机)和依靠并发传输(例如HDFS的数据多副本并发传输)。
epoll
操作系统级别提供了一些接口来支持IO多路复用,最早的是select、poll,其后epoll是Linux下的IO多路复用的实现。
- select接口最早实现存在需要调用多次、线程不安全以及限制只能监视1024个链接的问题
- poll接口修复了select函数的一些问题,但是依然不是线程安全的。
- epoll接口修复了上述的问题,并且线程安全,会通知具体哪个连接有新数据。
- epoll通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知(不再需要遍历文件描述符,通过监听回调的机制,也是epoll的魅力)
水平触发与边缘触发
epoll除了性能优势,还有一个优点——同时支持水平触发(Level Trigger)和边沿触发(Edge Trigger)。
- 水平触发只关心文件描述符中是否还有没完成处理的数据,如果有,不管怎样epoll_wait,总是会被返回。简单说——水平触发代表了一种“状态”。
- 边沿触发只关心文件描述符是否有新的事件产生,如果有,则返回;如果返回过一次,不管程序是否处理了,只要没有新的事件产生,epoll_wait不会再认为这个fd被“触发”了。简单说——边沿触发代表了一个“事件”。
边沿触发把如何处理数据的控制权完全交给了开发者,提供了巨大的灵活性。比如,读取一个http的请求,开发者可以决定只读取http中的headers数据就停下来。在边沿触发下,开发者有机会更精细的定制这里的控制逻辑。
信号驱动IO
在通道中安装一个信号器:映射到Linux操作系统中,这就是信号驱动IO。应用进程在读取文件时通知内核,如果某个 socket 的某个事件发生时,请向我发一个信号。
阻塞IO模型、非阻塞IO模型、IO复用模型和信号驱动IO模型都是同步的IO模型。原因是因为,无论以上那种模型,真正的数据拷贝过程,都是同步进行的。
AIO
用了AIO可以废弃select,poll,epoll。
linux的AIO的实现方式是内核和应用共享一片内存区域,应用通过检测这个内存区域(避免调用nonblocking的read、write函数来测试是否来数据,因为即便调用nonblocking的read和write由于进程要切换用户态和内核态,仍旧效率不高)来得知fd是否有数据,可是检测内存区域毕竟不是实时的,你需要在线程里构造一个监控内存的循环,设置sleep,总的效率不如epoll这样的实时通知。
相关资料
- 操作系统层面理解IO:https://www.cnblogs.com/twoheads/p/10712094.html
- 图解IO:https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41#wechat_redirect
- 把钓鱼过程,可以拆分为两个步骤:1、鱼咬钩(数据准备)。2、把鱼钓起来放进鱼篓里(数据拷贝)。
- 烧水的报警器一响,整个烧水过程就完成了。水已经是开水了。
- 钓鱼的报警器一响,只能说明鱼儿已经咬钩了,但是还没有真正的钓上来。
Java 中的网络支持
基本概念
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;f
- Datagram:使用 UDP 协议实现网络通信。
java BIO(Blocking IO 阻塞)
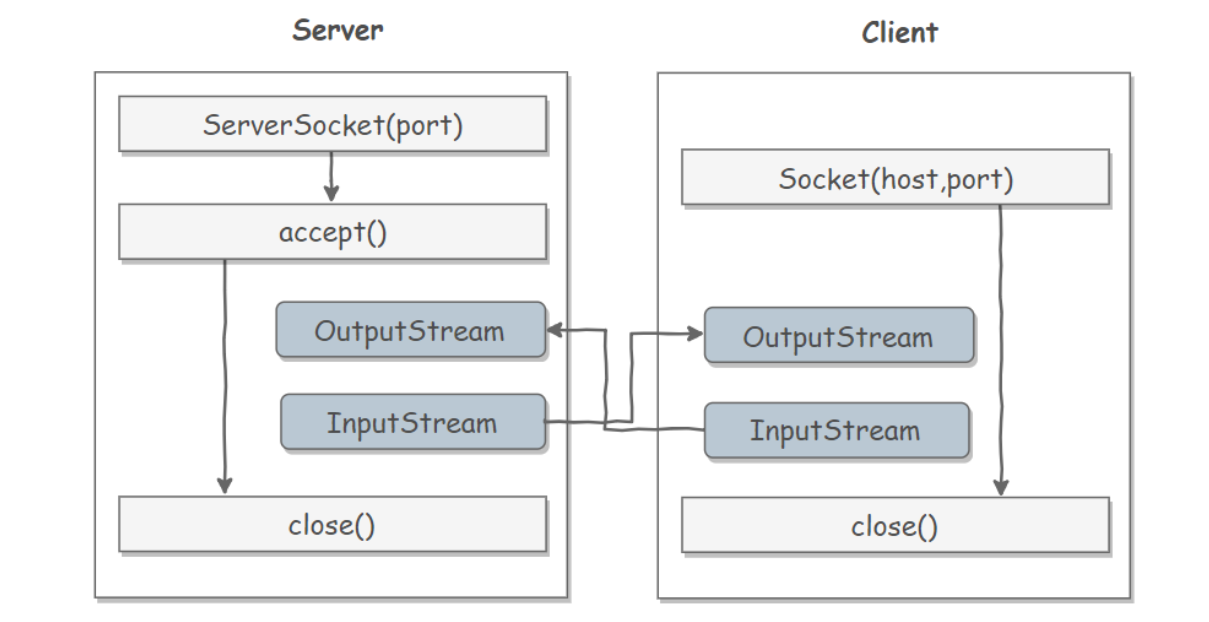
- 在不考虑多线程的情况下,BIO是无法处理多个客户端请求的。
- BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。
- 多线程情况下对于服务端,服务端只能用线程开启多个线程与客户端建立连接。
BIO多线程情况下的缺点:内存消耗、线程上下文切换
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU 使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
java NIO(Non-blocking/New I/O)
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
- 首先需要注册当这几个事件到来的时候所对应的处理器,事件处理完毕移除SelectKey,若未移除,selector不会检查这些key是否有事件到来。
- 然后在合适的时机告诉事件选择器:对这个事件感兴趣。
- 其次,用一个死循环选择就绪的事件,会执行系统调用,还会阻塞的等待新事件的到来。(系统调用指的是操作系统的函数调用,Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP)
- 新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
- 注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。
select会进行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
- NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。
零拷贝
IO的拷贝:
- 硬件(网卡)拷贝内核缓冲区 (读)
- 内核缓冲区拷贝到用户缓冲区 (读)
- 用户空间再拷贝到内核空间中的Socket buffer/Write buffer中。(写)
- 最后再从Socket buffer中拷贝到网卡缓冲区/硬件资源中。(写)
零拷贝的实现:
使用直接内存,在内核缓冲区中开辟一块用户空间和内核空间共享的直接内存区域,减少了用户缓冲区的复制操作。
事件驱动模型
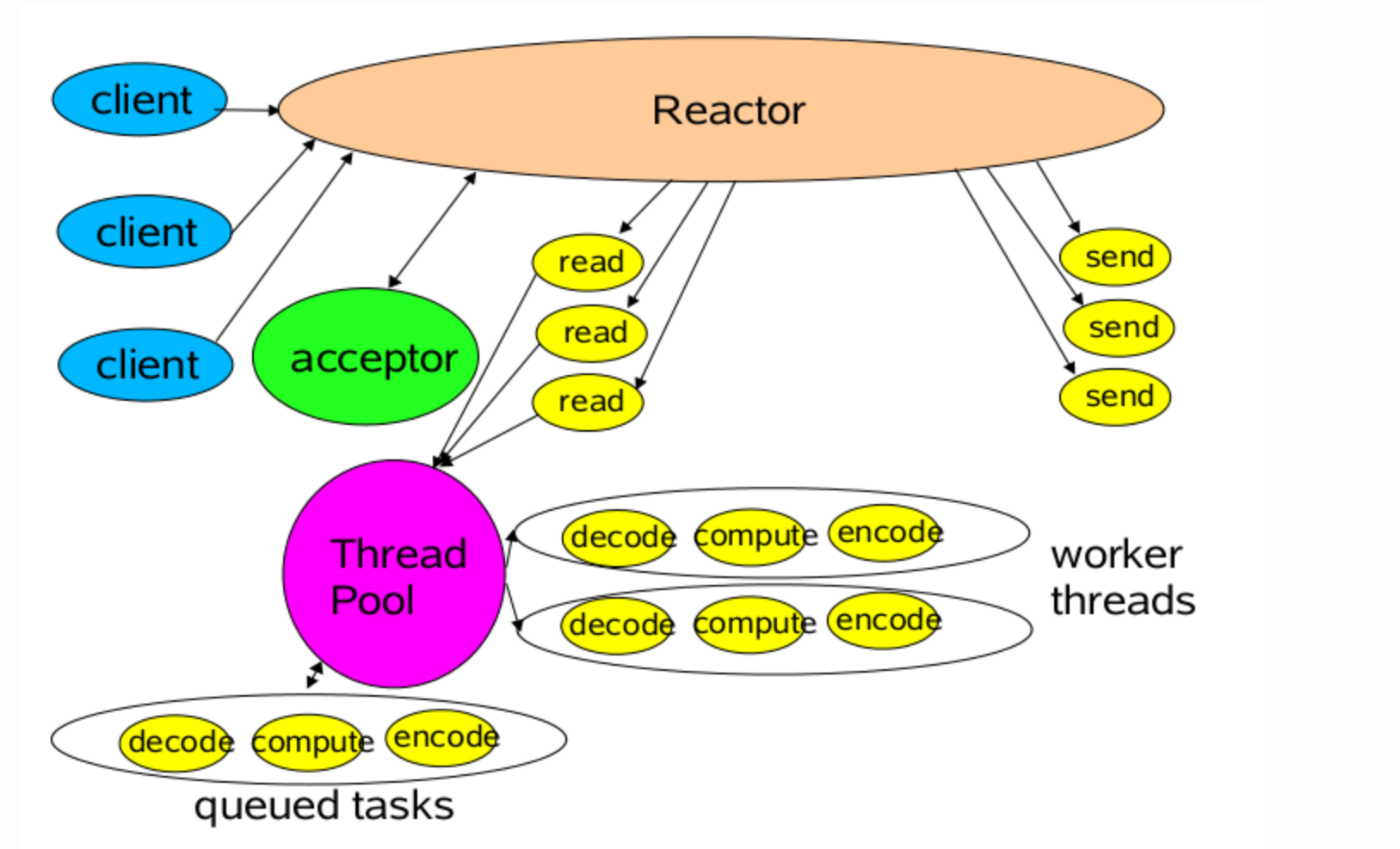
Reactor模式首先是事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。
Java的Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。另外连接的处理和读写的处理通常可以选择分开,这样对于海量连接的注册和读写就可以分发。虽然read()和write()是比较高效无阻塞的函数,但毕竟会占用CPU,如果面对更高的并发则无能为力。
1 | |
相关资料:
- NIO selectKey原理:https://blog.csdn.net/qq_32331073/article/details/81132937
- 美团NIO浅析: https://tech.meituan.com/2016/11/04/nio.html
NIO与BIO区别
- 通讯方式:NIO 通过Channel(通道) 进行读写,通道是双向的,可读也可写。而BIO使用的流读写是单向的。
- BIO流是阻塞的,NIO流是不阻塞的。
- BIO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
- 在面向流的I/O中·可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
- 在NIO厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
NIO 带来了什么
- 避免多线程
- 非阻塞I/O,I/O读写不再阻塞,而是返回0
- 单线程处理多任务
- 基于block的传输,通常比基于流的传输更高效
- 更高级的IO函数,zero-copy
- 事件驱动模型
- IO多路复用大大提高了Java网络应用的可伸缩性和实用性
Proactor与Reactor
在Reactor中实现读
- 注册读就绪事件和相应的事件处理器。
- 事件分发器等待事件。
- 事件到来,激活分发器,分发器调用事件对应的处理器。
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
在Proactor中实现读:
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分发器等待操作完成事件。
- 在分发器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分发器读操作完成。
- 事件分发器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分发器。
- 两者也有相同点:事件分发器负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调handler;
- 不同点在于,异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read 或 can write)。
RMI 远程方法调用
java支持,最早的远程调用,使用Remote接口,同时实现类别需要继承UnicastRemoteObject
通过Registry,注册发现远程方法,并调用接口。
netty
Netty 是一个 基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。
- 它极大地简化并优化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。
- 支持多种协议 如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
支持多个交互模型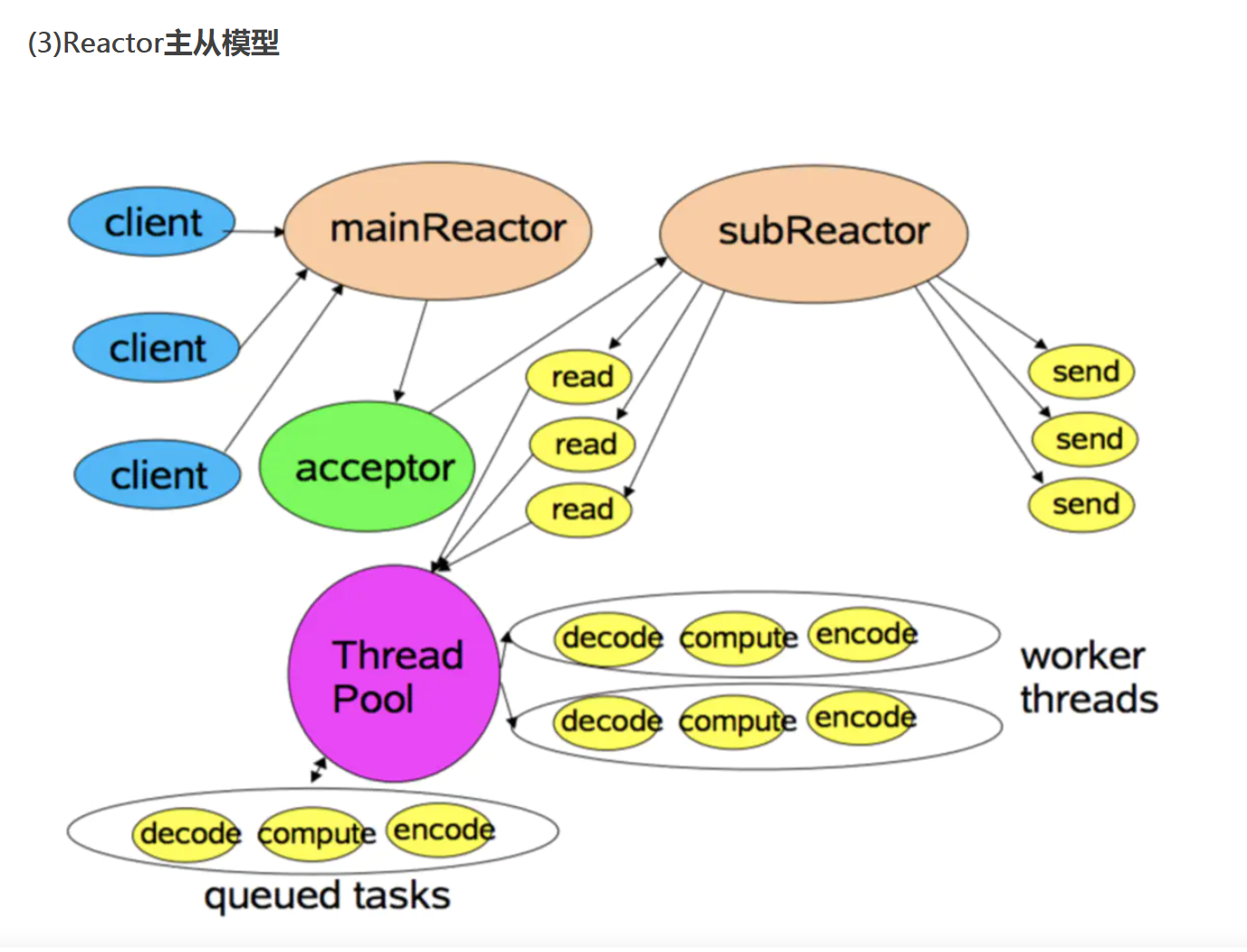
- Reactor分成两部分,mainReactor负责监听server socket,accept新连接;并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据,对业务处理功能,其扔给worker线程池完成。
Netty中的事件分为Inbond事件和Outbound事件。
- Inbound事件通常由I/O线程触发,如TCP链路建立事件、链路关闭事件、读事件、异常通知事件等。
- Outbound事件通常是用户主动发起的网络I/O操作,如用户发起的连接操作、绑定操作、消息发送等。
相比NIO :
- NIO在面对断连重连、包丢失、粘包等问题时处理过程非常复杂。Netty的出现正是为了解决这些问题。
- 解决了JDK 的 NIO 底层由 epoll 实现,该实现饱受诟病的空轮询 bug 会导致 cpu 飙升 100%
- 通过代码封装,简化了服务端与客户端的代码交互。
- 数据直接复制到directBuffer的工作缓冲区