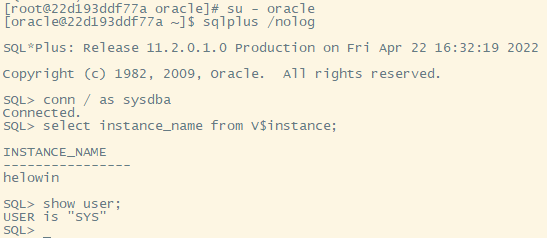
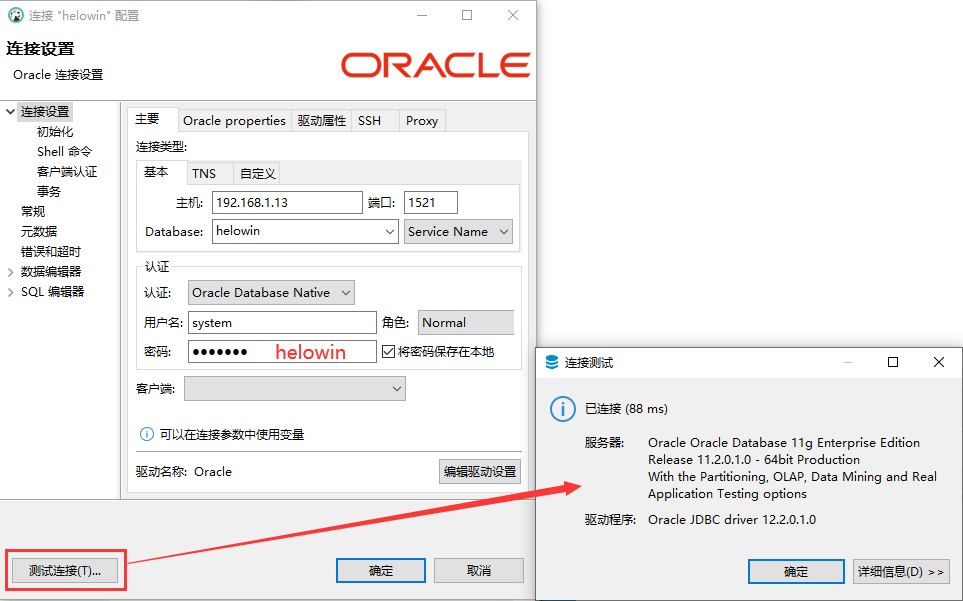
1.首先,创建(新)用户: createuser username identified by password; username:新用户名的用户名 password: 新用户的密码 也可以不创建新用户,而仍然用以前的用户,如:继续利用scott用户
2.创建表空间: createtablespace tablespacename datafile 'd:\data.dbf' size xxxm; tablespacename:表空间的名字 d:\data.dbf':表空间的存储位置 xxx表空间的大小,m单位为兆(M) 3.将空间分配给用户: alert user username default tablespace tablespacename; 将名字为tablespacename的表空间分配给username 4.给用户授权: grant create session,create table,unlimited tablespace to username; 5.然后再以楼主自己创建的用户登录,登录之后创建表即可。 conn username/password;6.查看服务名env |grep SID 7.授予dba权限grant dba to username7.使用上面的用户名、密码、sid登录plsql 每步执行的sql:(sjzx是数据库名、用户名、密码、表空间名) (1)create user sjzx identified by sjzx (2)create tablespace sjzx datafile 'D:\db\app\oradata\orcl\sjzx.dbf' size 100m autoextend on next 32m maxsize 2048m (3)alter user sjzx default tablespace sjzx (4)grant create session,create table,unlimited tablespace to sjzx 1.创建用户 create user user_name identified by "user_password" default tablespace tbs_name temporary tablespace temp profile DEFAULT; 2.授权 grant connect to user_name; grant create indextype to user_name; grant create job to user_name; grant create materialized view to user_name; grant create procedure to user_name; grant create public synonym to user_name; grant create sequence to user_name; grant create session to user_name; grant create table to user_name; grant create trigger to user_name; grant create type to user_name; grant create view to user_name; grant unlimited tablespace to user_name; alter user user_name quota unlimited on tbs_name;
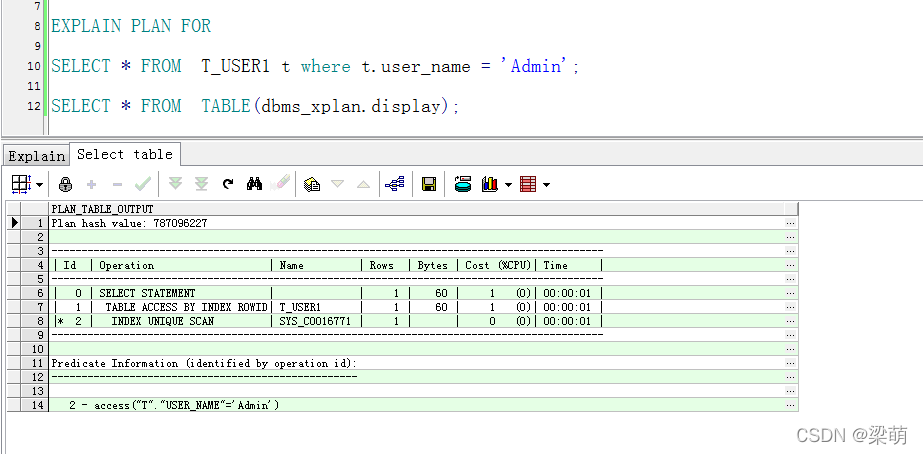
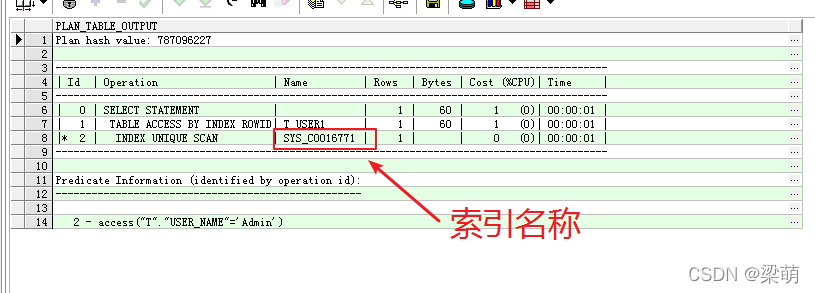
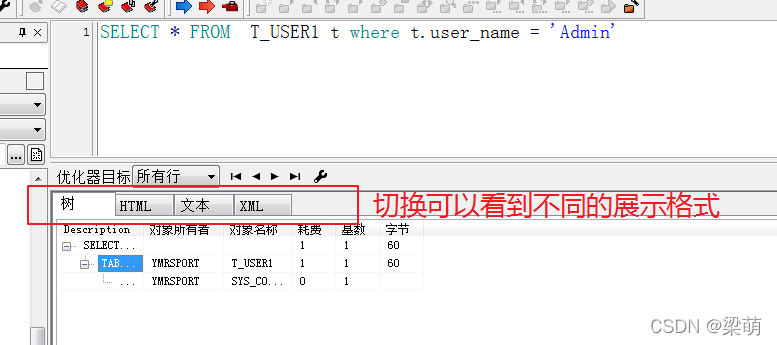
在oracle命令行中,查看oracle表空间数据文件位置 select t1.name,t2.name from v$tablespace t1,v$datafile t2 where t1.ts# = t2.ts#;
三、ORACLE 数据库:表的创建、修改与删除、数据增删改
1、创建表:
CREATE TABLE 表名称(
字段名 类型(长度) primary key,
字段名 类型(长度),
…….
);
1 2 3 4 5 6 7
CREATETABLE stu( id number primary key, name char(30), age number );
2、修改表
①增加字段语法:
ALTER TABLE 表名称 ADD(列名 1 类型 [DEFAULT 默认值],列名 1 类型
[DEFAULT 默认值]…)
1 2 3
ALTERTABLE stu ADD( sex char(30) );
②修改字段语法:
ALTER TABLE 表名称 MODIFY(列名 1 类型 [DEFAULT 默认值],列名 1 类型
[DEFAULT 默认值]…)
1 2 3 4
修改字段的类型 ALTERTABLE stu MODIFY( sex varchar2(30) );
③.修改字段名语法:
ALTER TABLE 表名称 RENAME COLUMN 原列名 TO 新列名
1
ALTERTABLE stu RENAME COLUMN sex TO gender;
④删除字段名
ALTER TABLE 表名称 DROP COLUMN 列名
1
ALTERTABLE stu DROPCOLUMN gender;
3、删除表
DROP TABLE 表名称
1
DROPTABLE stu
4、数据增删改
执行 ‘增删改’ 后要再执行 commit 提交事务。
1、插入数据
INSERT INTO 表名[(列名 1,列名 2,…)]VALUES(值 1,值 2,…)
1 2 3 4 5
insertinto stu values(1,'张三',18,'男'); insertinto stu values(2,'李四',30,'男'); insertinto stu(id,name,sex) values(3,'王五','男');
commit; --提交事务
2、修改数据
UPDATE 表名 SET 列名 1=值 1,列名 2=值 2,….WHERE 修改条件;
1 2 3
update stu set name='张三三'where id=1;
commit;
3、删除数据
DELETE FROM 表名 WHERE 删除条件;
1 2 3
deletefrom stu where id=1;
commit;
5、单表查询
1、简单条件查询
①精确查询
1
select*from stu where id=1;
②模糊查询
1
select*from stu where name like'%张%';
③and 运算符
1
select*from stu where name like'%张%'and id=1;
④or 运算符
1
select*from stu where name like'%张%'or age=30;
⑤范围查询
1 2 3
select*from stu where age>=10and age<=20;
select*from stu where age between10and20;
⑥空值查询
1 2 3 4
select*from stu where age isnull;
select*from stu where age isnotnull;
2、去掉重复记录
①不重复显示姓名
1
selectdistinct name from stu;
3、排序查询
①升序排序
1
select*from stu orderby age;
②降序排序
1
select*from stu orderby age desc;
4、基于伪列的查询
在 Oracle 的表的使用过程中,实际表中还有一些附加的列,称为伪列。
伪列就像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作。
① ROWID 返回的是该行的物理地址
1
select rowid,s.*from stu s;
②ROWNUM 为结果集中每一行标识一个行号
1
select rownum,s.*from stu s;
5、聚合统计
①求和 sum
1
selectsum(age) from stu;
②求平均 avg
1
selectavg(age) from stu;
③求最大值 max
1
selectmax(age) from stu;
④求最小值 min
1
selectmin(age) from stu;
⑤统计记录个数 count
1
selectcount(*) from stu;
⑥分组聚合 Group by
1 2
--按性别分组统计年纪 select sex,sum(age) from stu groupby sex;
--1、创建物化视图 create materialized view mv_stu as select*from stu ;
--插入一条数据 insertinto mv_stu values(4,'赵六',18,'女');
--手动刷新物化视图 begin dbms_mview.refresh('mv_stu','c') end;
--2、创建自动刷新的物化视图 create materialized view mv_stu2 refresh oncommit as select*from stu;
--3、创建时不生成数据的物化视图 create materialized view mv_stu3 build deferred refresh oncommit as select*from stu ;
--执行下列语句生成数据 begin dbms_mview.refresh('mv_stu3','c') end;
--4、创建增量刷新的物化视图 --首先创建物化视图日志 create materialized view log on stu with rowid; --创建物化视图 create materialized view mv_stu4 refresh oncommit as select s.rowid rowid,s.*from stu s;
十、序列
①创建与使用简单序列
create sequence 序列名称
提取下一个值:select 序列名称.nextval from dual
提取当前值:select 序列名称.currval from dual
②创建复杂序列
1 2 3 4 5 6 7 8
CREATE SEQUENCE sequence //创建序列名称 [INCREMENT BY n] //递增的序列值是n 如果n是正数就递增,如果是负数就递减 默认是 1 [STARTWITH n] //开始的值,递增默认是 minvalue 递减是 maxvalue [{MAXVALUE n | NOMAXVALUE}] //最大值 [{MINVALUE n | NOMINVALUE}] //最小值 [{CYCLE| NOCYCLE}] //循环/不循环 [{CACHE n | NOCACHE}];//分配并存入到内存中
declare t_stu stu%rowtype; cursor cur_stu isselect*from stu where id=1 ;-- 定义游标
begin
open cur_stu; -- 打开游标 loop fetch cur_stu into t_stu ;-- 提取游标到变量 exit when cur_stu $notfound;-- 当游标到最后一行下面退出循环 dbms_output.put_line(t_stu.id,t_stu.name); end loop; close cur_stu ;-- 关闭游标
end;
-------带参数的游标
declare t_stu stu%rowtype; cursor cur_stu(t_id number) isselect*from stu where id=v_id ;-- 定义游标
begin
open cur_stu(1); -- 打开游标 loop fetch cur_stu into t_stu ;-- 提取游标到变量 exit when cur_stu $notfound;-- 当游标到最后一行下面退出循环 dbms_output.put_line(t_stu.id,t_stu.name); end loop; close cur_stu ;-- 关闭游标
end;
------for 循环提取游标值 declare t_stu stu%rowtype; cursor cur_stu(t_id number) isselect*from stu where id=v_id ;-- 定义游标
begin
for t_stu in cur_stu(1) loop dbms_output.put_line(t_stu.id,t_stu.name); end loop; end;
createor replace procedure pro_stu_add1( t_name varchar(30), t_age number, t_sex varchar(30), t_id out number ); is select seq_stu.nextval insertinto t_id from dual; begin insertinto stu values(t_id,t_name,t_age,t_sex); commit; end;
--调用 declare id number;-- 定义传出参数的变量 begin pro_stu_add1('小王',20,'女',id); DBMS_OUTPUT.put_line('增加成功,ID:'||id); end;
-- 创建后置触发器,自动记录更改前后日志 createtrigger tri_stu_log after updateof name on stu foreachrow declare begin insertinto stu_log values(sysdate,:old.id,:old.name,:new.name); end;
-- 更新数据 update stu set name='张三三'where id=1; commit;